楔子
最近想深入学习Spark,因此尝试阅读Spark的源码。个人任务阅读源码是有一些挑战的,需要思考作者当初为什么要这样设计,设计之初解决的问题是什么。
在对Spark的源码进行具体的走读之前,如果想要对Spark有一个快速的整体认识,优先阅读matei Zaharia的Spark论文是一个非常不错的选择。
在阅读该论文的基础之上,再结合Spark作者在2012年Developer Meetup上做的演讲Introduction to Spark Internals,那么对与Spark的内部实现上会有一个整体上的了解。
基本概念(Basic Concepts)
RDD - resillient distributed dataset 弹性可分布式数据集
Operation - 作用于RDD的各种操作分为transformation和action
Job - 作业,一个JOB包含多个RDD及作用于RDD上的各种Operation
Stage - 一个作业分为多个阶段
Partition - 数据分区,一个RDD中的数据可以分成多个不同的区
DAG - Directed Acycle Graph 有向无环图,反应RDD之间的依赖关系
Narrow dependency - 窄依赖,子RDD依赖于父RDD中固定的data partition
Wide Dependency - 宽依赖,子RDD对父RDD中所有的data partition都有依赖
Caching Managenment - 缓存管理,对RDD的中间计算结果进行缓存管理以加快整体的处理速度
编程模型(Programing)
RDD是只读的数据分区集合,注意是数据集
作用于RDD上的Operation分为transformation和action。经Transformation处理之后,数据集中的内容会发生改变,由数据集A转换为数据集B;而经过Action处理之后,数据集中的内容会被归约为一个具体的数值。
只有当RDD上有action时,该RDD及其父RDD上的所有operation才会被提交到cluster中真正的被执行。
从代码到动态运行涉及到的组件如下图所示:
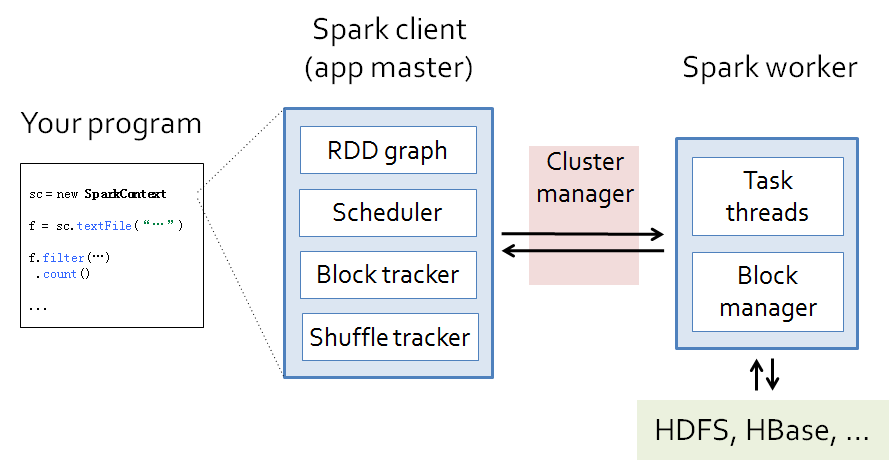
演示代码:
val sc = new SparkContext("Spark://...", "MyJob", home, jars)
val file = sc.textFile("hdfs://...")
val errors = file.filter(_.contains("ERROR"))
errors.cache()
errors.count()
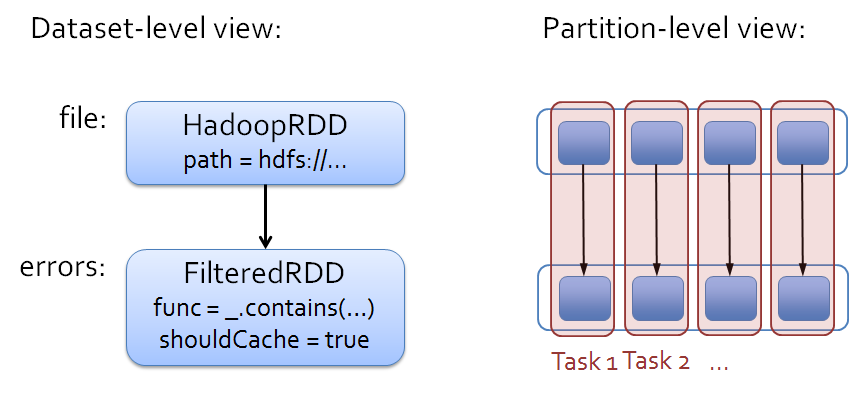
运行态(Runtime view)
不管什么样的静态模型,其在动态运行的时候无外乎由进程,线程组成。由Spark的术语来说,static view成为dataset view,而dynamic view称为partition view。关系如图所示:
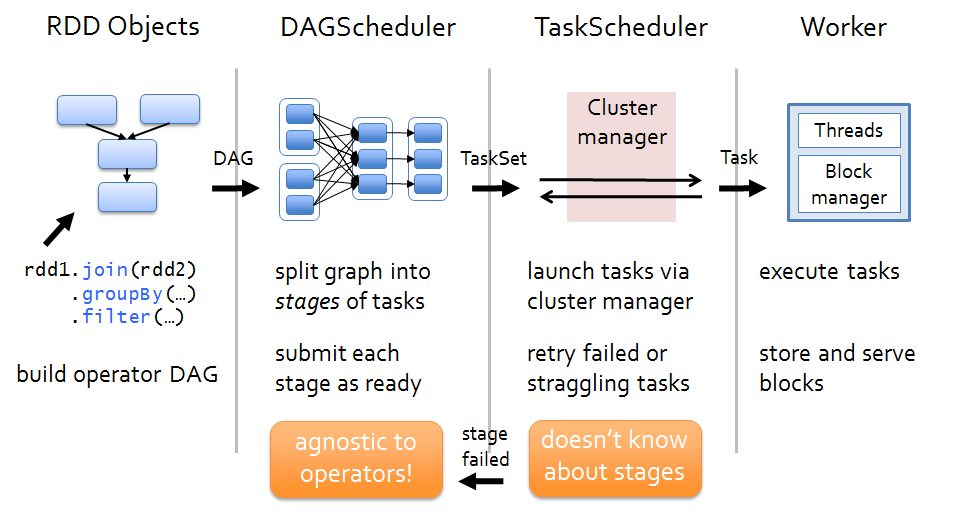
部署(Deployment view)
当有Actioin作用于某RDD时,该action会作为一个job被提交。
在提交的过程中,DAGScheduler模块接入运算,计算RDD之间的依赖关系。RDD之间的依赖关系形成了DAG.
每一个JOB被划分为多个stage,划分stage的一个主要依据是当前计算因子的输入是否确定。如果是则将其分在同一个Stae
,避免多个stage之间的消息传递开销。
当Stage被提交之后,由taskScheduler来根据stage计算所需要的task,并将task提交到对应的worker。
Spark支持以下几种部署模式1)standlone 2)Mesos 3) YARN。这些部署模式将作为taskScheduler的初始化参数。
RDD接口(RDD Interface)
RDD由以下几个主要部分组成
partitions - partition集合,一个RDD中有多少data partition
dependencis - RDD依赖关系
compute(partition) - 对于给定的数据集,需要做的计算
preferredLocations - 对于data partition的位置偏好
partitioner - 对于计算出来的数据结果如何分发
缓存机制(caching)
RDD的中间计算结果可以被缓存起来,缓存先选Memory,如果Memory不够的话,将会被写入到磁盘中。
根据LRU(last-recent update)来决定哪先内容继续保存在内存,哪些保存到磁盘
容错性(Fault-tolerant)
task运行咋icluster之上,除了Spark自身提供的standalone部署模式之外,spark还支持YARN和Mesos
Yarn来负责计算资源的调度和监控,根据监控结果重启失效的task或者是重新distributed task,一旦有新的ode加入cluster的话。
这一部分的内容需要参看yarn的文档。
小结
在源码阅读时,需要重点把握以下两大主线。
静态view即RDD,transformation and action
动态view即life of a job,每一个job又分为多个stage,每一个stage又包含多个rdd及transformation,这些stage又是如何映射成为task被distributed到cluster中。